Organising qualitative data into asset databases to standardise reports and improve BIM practices
This report describes the implementation of a data-driven approach to report creation for more efficient, standardised outputs.
Vast amounts of information are required to plan, manage, and deliver the High Speed Two (HS2) railway. This information is traditionally delivered in the form of documents or reports.
Many of these documents need to be delivered in standardised formats, particularly those used to obtain approvals from consenting bodies or to provide consistent information to other members of the supply chain. Furthermore, the data populating these reports must be consistent and up to date across various reports.
Due to the volume of information, optimising the production and management of this information to save time and money represents a significant opportunity to bring value to this project and the wider construction industry. This paper describes the steps taken to optimise the production of standardised documents to seize this opportunity and respond to challenges encountered early in the project. The approach described uses a central database to store the various required report templates & qualitative data used to populate these reports. The industry focus thus far has been limited to the management of structured numerical information, and there have been few innovations to the process of producing reports. This paper therefore demonstrates an innovative solution to both report production and the use of qualitative data. The production of each report is completed within the central database, so that information is consistent and easily updated. The final step of report generation is converting the report to a PDF or Word Document with the necessary information already populated. Such an approach has implications beyond the scope of HS2, as this solution stores and links unstructured data in an innovative manner. This centralised database of data along with the recent advancements in Artificial Intelligence will provide further opportunities for delivery efficiencies on infrastructure projects.
- Written by
-
Shania Sandher (Mott MacDonald)

-
Matt Graham (Mott MacDonald)

-
James Barry (Mott MacDonald)

- Resource type
- Resource type: Technical Paper
- Intended audience
- Consultants
- Contractors
- Leadership Teams
- Private Sector Clients
- Public Sector Clients
- Tags
- Database structuring posts
- Information management posts
- standardisation posts
Background and industry context
This paper is presented as part of the works to deliver the Main Works Civils Contract (MWCC) for the northern section of High Speed Two (HS2) Phase One including Long Itchington Wood Green Tunnel to Delta Junction and Birmingham Spur and the Delta Junction to the West Coast Main Line (WCML) tie-in.
The HS2 Northern Main Works Civil Contracts delivered by a Balfour Beatty Vinci integrated project team in partnership with HS2, Mott MacDonald, Systra and SB3 requires the design and build of a diverse range of assets covering more than 80km (50 miles) of railway.
Across any major project, large volumes of valuable project information are created, stored, and shared between a comprehensive network of users. A common theme across such projects is that this information is often hard to find and use efficiently, recent advances in Information Management and Building Information Management (BIM) respond to these challenges. BIM and data practices have been found to deliver up to a 7% reduction in overall project delivery time (Stanford University – 1). That said, BIM practices must be carefully implemented to add value to the project. If information isn’t easy to find, there is a risk that people will choose to create it again. This is a major risk as it creates inconsistencies as the information is repeated often with differing conclusions. Furthermore, these various sources are then unlinked, requiring time-intensive manual effort if changes need to be made. The best practice to avoid this is it set up a common data environment (CDE) to allow people to find information quickly while ensuring accuracy.
This case study is on HS2, where a small template change needed to be made to thousands of word documents to reflect a new format. The existing approach was to edit these documents by hand, which was estimated to take more than 3 weeks to complete. This presented an opportunity to think differently as the scale of the challenge and the time to resolve the problem was unacceptable to the delivery program.
The type of information captured for any project ranges from structured, numerical information, often visualised graphically, through to unstructured, descriptive information presented in the form of text.
Storing large quantities of structured numerical information and repetitively applying complex calculations on these datasets whilst challenging is becoming more common place in infrastructure delivery. Projects such as Tideway, London Power Tunnels 2, Northern Line Extension, and more provide good examples. Data science methods have demonstrated the ability to store bigger datasets and process complex calculations faster, a simple example is Mott Macdonald’s overtopping tool which improved the calculation speed by over 1000x.
In contrast, unstructured descriptive information is an area that has not been explored with similar levels of success. Field research shows that the industry R&D focus is on the management of structured numerical information with limited focus on solutions for unstructured descriptive information. There have been few innovations in the unstructured information area, despite similar challenges (as noted above) with regards to time lost and similar financial and quality risks. Furthermore, few innovations have been made to the process of producing reports.
Existing solutions have largely focused on capturing and categorising unstructured information to enable more efficient and intelligent searching or creating new content following a similar style, based on different sets of information. These solutions rely upon file-based hierarchical folder structures as the basis for storing the information, implicitly accepting this system as a foundation for new solutions.
A file-based hierarchical system can be stored in a structured database table, shown in Figure 1. Information can be supplied with characterising metadata at row-level, such as when that information was created and by whom. However, it is not naturally feasible to apply this characterisation effort to the information contained in the form of text in a Microsoft Word document, for example. Such characterisation can be applied to the file itself, and the folders further up the hierarchical storage structure, but not the information contained inside them.
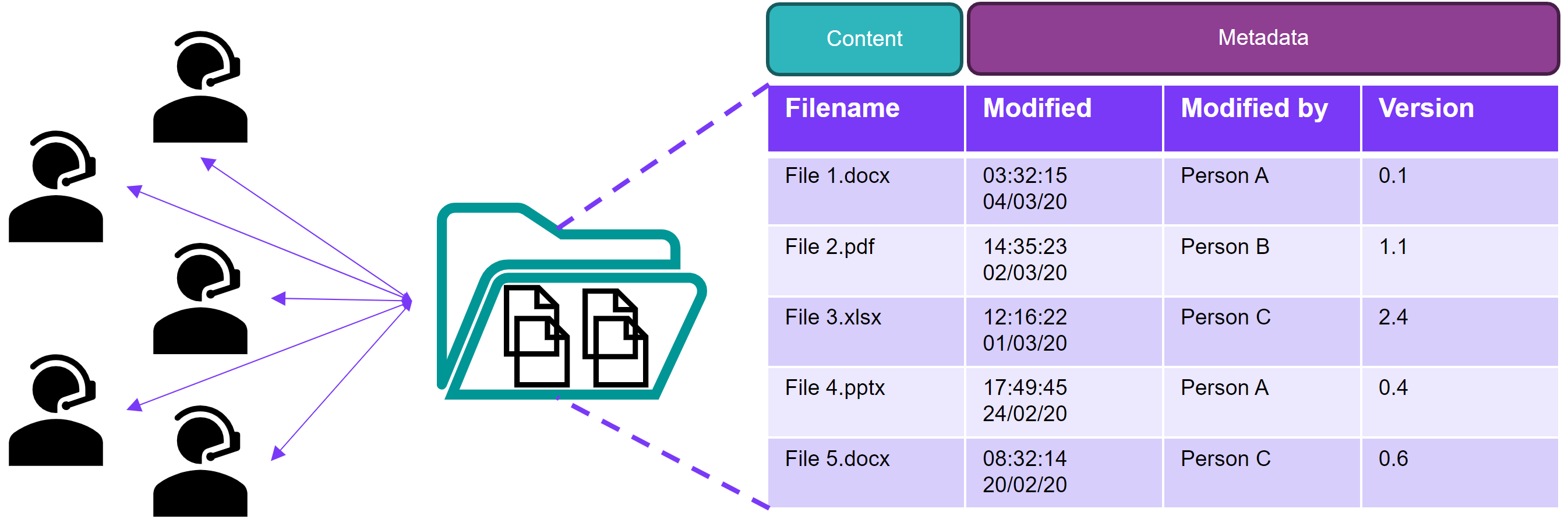
However, it is the information in these files that ultimately holds intrinsic value to the project, not the files themselves. So innovation in information management must focus on how to store, manage and share the information, not the files. Furthermore, the core tenet of this paper is that systems that treat files as the most granular focus of storage is a fundamentally flawed practice.
Approach
The challenge
In the context of HS2, the project team was presented with a challenge that involved the delivery of design approval documentation for hundreds of assets along the route. The documentation required several report deliverables in different styles, all to be delivered with consistent style and content depending on the assets.
Implementing a file-based management system, developing templates, and defining strict structures can establish style consistency from the outset. However, ensuring that any changes to templates or content structures are propagated across future documents – many of which may be in progress at the time of the change – requires labour-intensive, manual work with a high risk of human error.
Secondly, ensuring that narrative information remains consistent and up to date was not easily achievable using the original system. Changes to descriptive information had to be updated across all live documents, which would also require significant manual effort with a high risk of handling errors.
The challenge was to reduce the effort and risk in the established processes of ensuring consistency and accuracy of information across all documents, through the implementation of a new data management system.
The initial response
Once the number of documents to be generated had been identified and the standardised format agreed, it quickly became clear that process and technology were key to efficient production. Using the existing CDE set up in ProjectWise, a process was developed to quickly generate standardised Microsoft Word templates, pre-completed with asset data where appropriate. The templates were identified by hand with the HS2 team, and reviewed with the supply chain and third parties who would be receiving the reports. A template library was created to cover all required aspects, as shown in Figure 2. This allowed the team to effectively work across multiple documents and monitor production using data from dashboards built off the ProjectWise CDE. This included insights such as number of documents that had been produced and the state of the delivery workflow each was in.
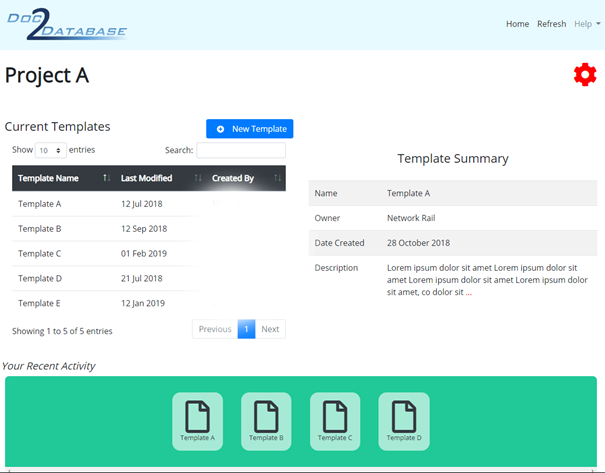
Although this approach was initially considered successful, a request for a minor amendment quickly identified a flaw. To change a single heading in each Microsoft Word document across more than 200 reports required significant manual effort and an unsustainable time delay, meaning further development was required. This approach focussed on the template aspect of the challenge, with the data as a secondary component.
As a substitute, a data-first approach was established. Data was captured accurately in a format whereby it can be re-used across all documents and stored in a single accessible location, as shown in Figure 3. Any changes now require just a single update to percolate across all output documents. Microsoft Access was used as the underlying technology which required team members to adjust their approach from editing individual documents to maintaining the centralized database, enforced through training. Production and approvals occurred within the database, so that outputting to the desired document was a final step, as opposed to a first step. This allowed data to be stored centrally, rather than within separate documents, so that the examination of output documents in either Microsoft Word or PDF format became purely a visual formality.
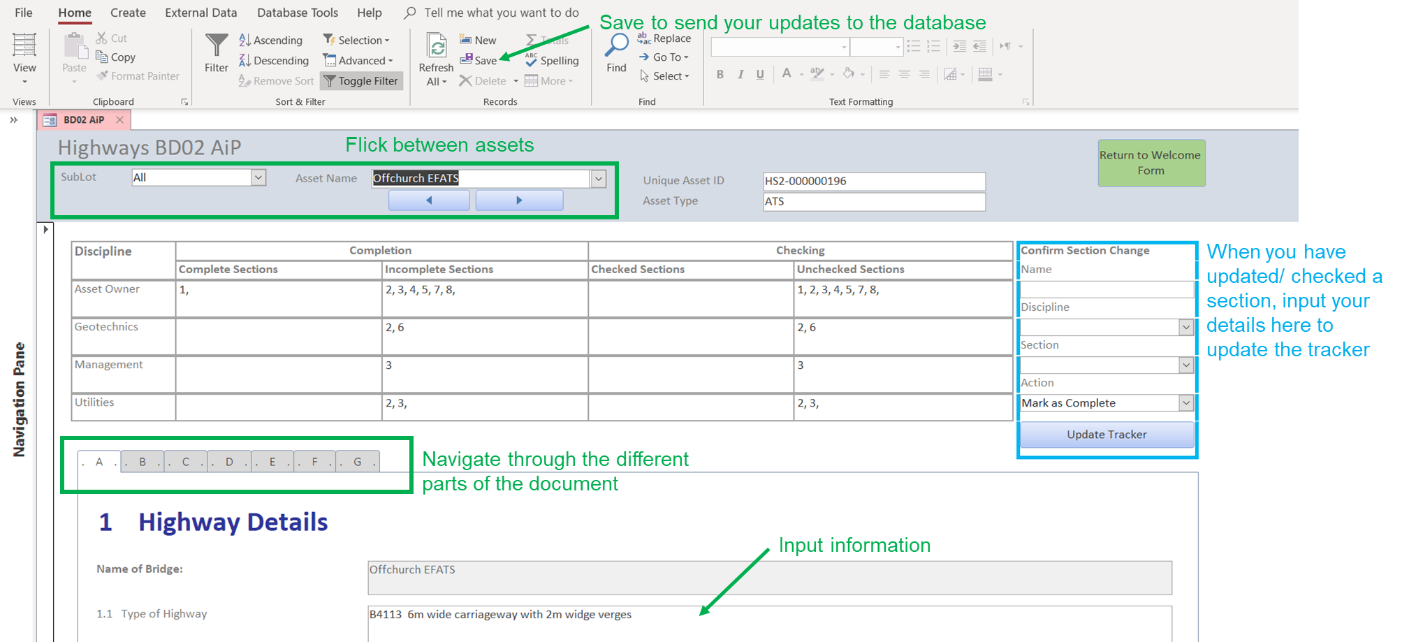
This new approach delivered improved efficiencies, particularly in the time needed to make updates or amendments. Efficiencies were also realised in quality and checking time due to having a ‘single source of truth’ approach to documentation. The team was trained on the new approach, and several unintended benefits were identified during uptake: the reduction of repeat checking, clearer responsibilities over content – each data field resided with a clear owner – and new behaviours across the team to standardise documents and input information once. Quite simply, a ‘quality, first time’ approach.
Further challenges
This solution demonstrated the value of the database and proved that unstructured qualitative data could be stored in a data-first approach. This developed interest over what else could be possible to further improve efficiency and accuracy in reporting. Could the database be connected to every future downstream calculation? Could the need to copy data into the database be removed? Consequently, a conceptual data architecture model was developed with the aim to minimise the re-production of data. This became the basis of the next iteration of the solution.
Throughout this journey, engaging and convincing people of the value of this approach was a major barrier. This was due to the high-pressure environment the team was under, which perceived the change in approach & adoption of new processes as a risk. This was overcome through training, regular engagement, understanding requirements early, and constantly obtaining feedback.
The final challenge was the size, access limitations, and long-term viability of the Microsoft Access database. Ad-hoc challenges and surprise failures brought added pressures to delivery days, requiring a review of the technology. Furthermore, increased reliance on the solution revealed limitations on the number of users able to access the database. Finally, the long-term sustainability of the physical database as opposed to cloud-based was questioned. These risks had become significant and unsustainable. While the underlying approach was working, the implementation with the Microsoft Access database proved to be unscalable with increasing use.
Maturing the data management approach
Based on the success of the implemented system, the decision was taken to upscale the previous solution, while incorporating the challenges identified during the proof-of-concept stage for the new data architecture model. This involved engaging a professional software development team and adopting agile, iterative approaches to defining requirements and developing the solution.
While defining requirements, the focus was on the end user – formalising roles and respective pain points across this userbase. These challenges were prioritised in terms of value to the user and served as the basis for designing the new solution. This prioritisation effort enabled the team to build a roadmap for implementation, aimed at iterative development, new features, and mapping the most efficient route towards a usable solution.
Several functional requirements were considered, including:
- Multiple users interacting with the same information at the same time
- Microsoft Access available to delivery partners across the entire HS2 Project
- Discipline-orientated checking and approval procedures
- Integration with the existing project CDE
However, key requirements focused on the management of unstructured project information, summarised by the following tenets:
- Information would never be stored more than once
- When information was required as part of a deliverable, it could be retrieved from its source and added into the required context
- Any changes to information in any given context would be reflected everywhere else it appeared
These advancements in requirements meant that the solution went beyond what we had achieved with Microsoft Access. Whereas Access could store project information and allow it to be exported to output documents, the process did not work the other way round: information couldn’t be edited in an output document and simultaneously updated at source. There was also no ability to ensure consistency of templates across the project. Furthermore, no combination of Microsoft Word and the wider CDE could realistically enable checking and approval processes to be oriented around the disciplines involved in the production of each document – instead, these processes had to revolve around the output document itself. The evolved solution aimed to address all these shortcomings.
The development strategy for this solution was to minimise and democratise the configuration cycle, so it can be applied to any project deployment. All too often, solutions are built with a major project in mind. In such cases, implementation can be limited in its application to other projects, requiring additional development work. Additionally, the effort to configure a project for any given scenario can be both highly technical and time intensive.
The configuration cycle was minimised, with the aim to quickly deliver the critical components of any project and add further configuration once initial users were onboarded. The cycle was also democratised, to bring the configuration effort into the hands of users. This has users interact at the earliest stage possible in deployment and upskills users in their understanding of how the approach works. This reduces the ‘black box effect’ where users blindly use a new system without insight into the underlying processes.
Outcomes
The updated solution
A solution was created comprising the following high-level architecture:
- A series of tables stored in a cloud-hosted database
- A web browser-based user interface for preparing documents, Figure 4
- An additional user interface enabling ‘back-office’ editing of project information, Figure 5
- An application programming interface (API) to retrieve and deliver content between the database ‘back-end’ and either of the user interfaces
Overlaying this foundation, additional features were added to give users control over information characteristics via the user interfaces. Such features included:
- Enable checking and approval at each section of a deliverable, empowering individual disciplines to control the maturity and readiness of the information they are responsible for
- Ability to export to fully formatted, ready-to-issue Microsoft Word documents, as required for compliance and integration with the project CDE
The rationale behind implementing the back-end storage component was that content would be stored in the tables as JSON: a data format that stores an array of information using ‘attribute-value’ pairs. For example, an attribute of any JSON object might be:
- Overbridge length: 72m
- Document section 2, paragraph 1: [paragraph text]
- Section status: Editing
- Asset linked to document: Asset 5
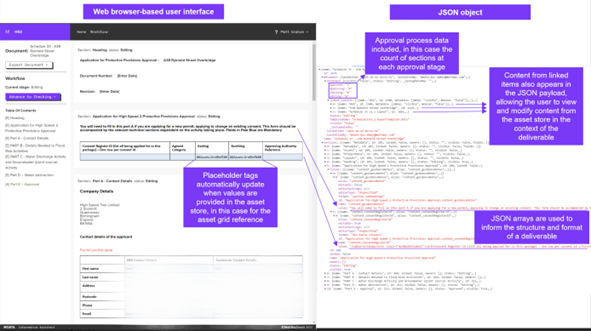
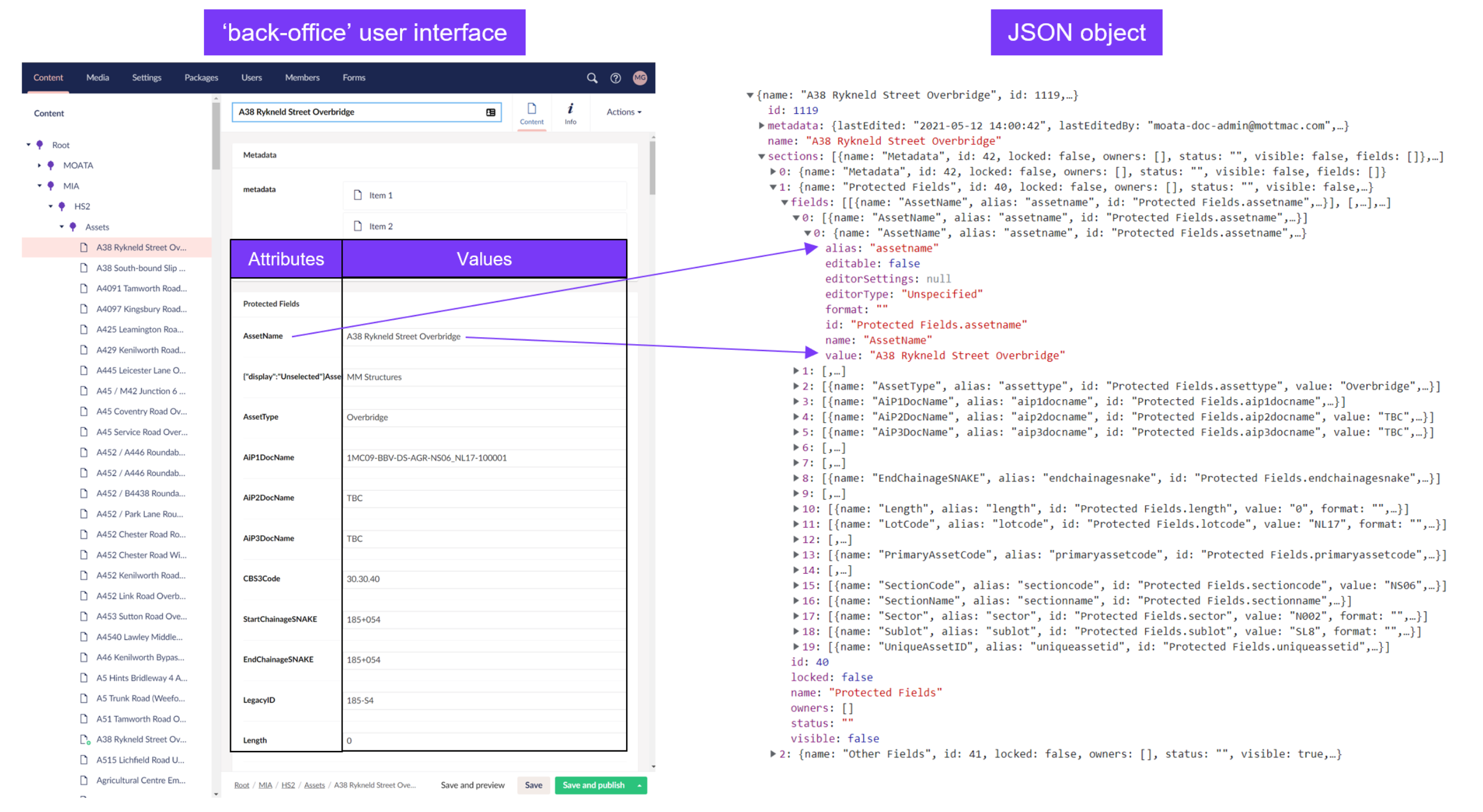
- The benefit of using this approach to content storage and structure is its flexibility. It is structured in a human-readable format and can also be read by software applications and presented in user interfaces in any context for any purpose, as demonstrated in Figures 4 and 5 above.
- As an example, consider a lead author for the project, tasked with the delivery of several documents across multiple assets, as is the case with HS2. The solution allows all standard, descriptive information for any asset to be stored such that it can be brought into any deliverable. The act of preparing a report deliverable on the project involves three stages:
- Creating the report based on a template populated with ‘boilerplate’ content
- Establishing a link between the deliverable and the correct asset, and auto-populating any asset content based on the placeholder tags in the template
- Updating any asset content at source, from the context of the deliverable, and then adding any final content specific to the deliverable
The deliverable approval process for the author has been made much quicker through the efficacy of preparation, and confidence that asset content is up-to-date. This improved approach required less training with higher ease of use, due to the more intuitive interface compared to the Microsoft Access database.
Some questions can be asked about the solution, specifically around the choice of data structure. JSON is simple and flexible but structured differently compared to databases with defined schemas. Defined schemas are likely to be more accessible to users, with data presented in the same way as an everyday Excel spreadsheet.
However, the simple answer for choosing JSON is that the stored content required significant characterisation. As well as the value of any array attribute, understanding, for example, when that value was changed, and by whom, was critical to providing an auditable history to any deliverable. Another reason was the need to define the workflow status of increasingly granular content – in some cases down to a single attribute.
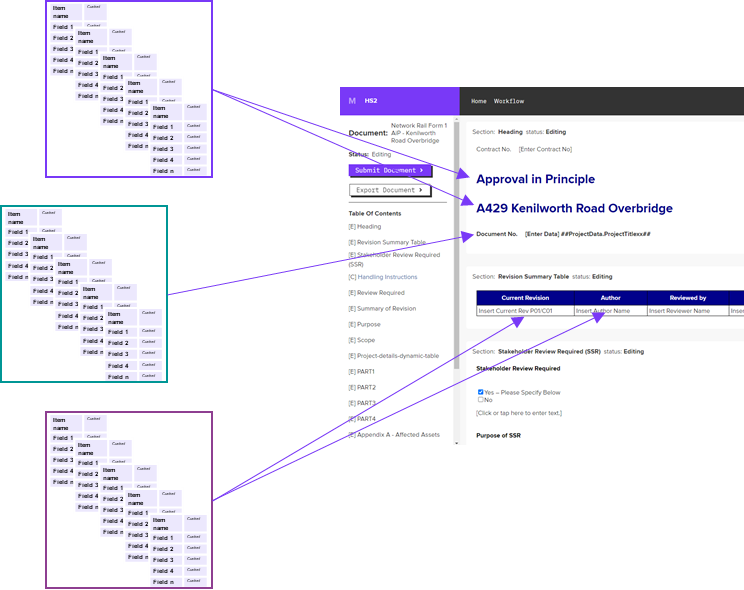
These requirements that can be easily resolved by adding further descriptive attributes to any level of a JSON object’s content hierarchy and is the main reason for this approach (figure 6).
Through the first 18 months of use, the implementation of this final solution had an estimated total value gained of just under £30k, with 1350 updates made to new documents, 176 new documents created, and 688 updates made to assets. Key benefits of the solution included reducing time spent authoring documents by up to 80%, freeing teams from repetitive, error-prone tasks, and connecting data for improved insights.
Learnings and recommendations
Scalability
While the initial incentive was to develop this upscaled solution for HS2, the secondary intention was to ensure the solution could be scaled laterally to other project types. This proved possible because the solution relied upon the type of data used in HS2, not the specific information. While this approach can be openly implemented following the details provided in this paper, this solution was also developed into a product, Moata Information Architect. This is a solution to a highly common challenge concerning the use and management of unstructured text-based data across the Architectural Engineering and Construction (AEC) industry, in particular projects which handle staged deliverable gateways for multiple assets across major frameworks. In the future, it is expected that projects will require this solution as a standard way of working. While this solution has progressed through multiple tools with increasingly complex data models, the core approach is consistent: centralising data before creating the reports as a final output. This allows work to be completed in a common area where changes can be made easily and efficiently. The legacy from this approach is the concept, which can be expanded and developed depending on the project requirements & team skill level.
To date, the solution has been deployed on a variety of projects, inside and outside of HS2. This ranges from frameworks as indicated above, to bid processes and content management, through to individual technical disciplines endeavouring to standardise their most common deliverable types. End users have been fully involved in the configuration process, as well as follow-on changes to configurations during deployment lifecycles.
Implementing this approach can be broken down into three main steps. First, consider how the relevant data can be managed and map the process to create reports as an output. Second, understand the size and scale of the data to create a proportionate solution. Third, place ownership of the development of the tool within the discipline or team that will be the ultimate end user.
The concept of storing content using this approach has provided a breadth of opportunities across a range of other software solutions, bringing value to an even broader range of stakeholders than would have been possible as an isolated solution. In many ways, the greatest value has been in the solution’s capacity to operate as a ‘content engine’ – providing a flexible, versatile backbone for storing and managing all types of content in an AEC industry solution platform, shown in Figure 7. Examples include project update notifications, legal content, user guidance content, video content, and so much more.
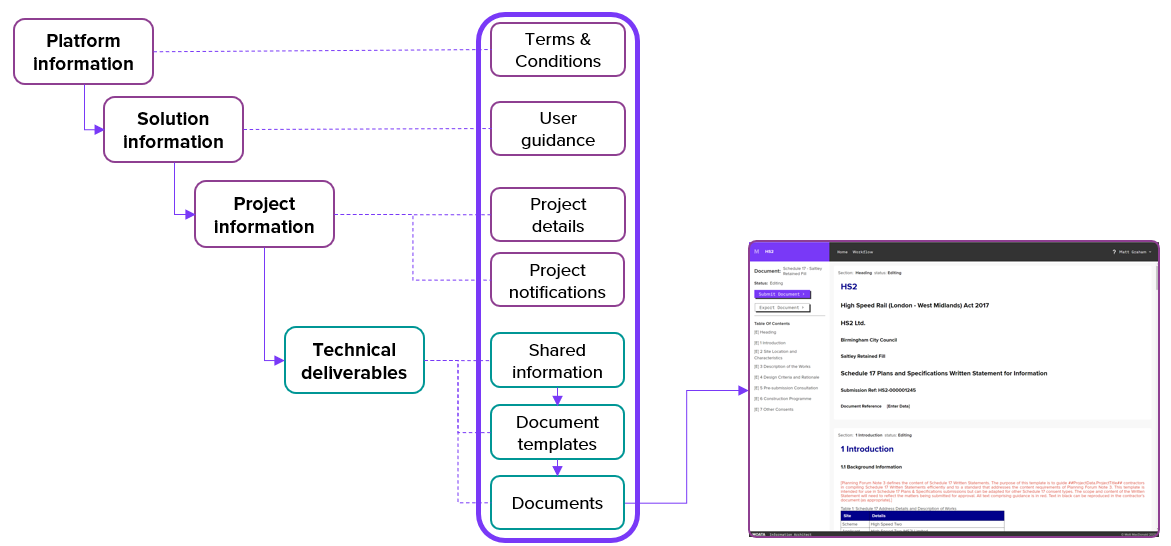
This scaling, benefitting stakeholders across a myriad of projects, sectors and countries, would not have been possible without the iterative development approach and collaboration across HS2 teams as the solution has grown from prototype to enterprise-grade software.
Conclusion
This HS2 Project has migrated from manual report production to a fully automated and intelligent data-first solution. Through this journey, the benefits have been measured against the original baseline, with an estimated total value gained of nearly £30k in document production over the first 18 months and up to 80% reduction in time spent writing reports. This case study concludes that data management should be considered at the outset to improve efficiency in delivery. The need to produce standardised outputs enabled the opportunity to take a data-first approach to develop, manage, and produce intelligent reports. The Project has evolved this approach to connect datasets to reduce manual effort, improve data quality, and ultimately produce high-quality trusted outputs. The value of this approach has been realised on this HS2 Project and is being shared so future projects can instead adopt a data-first approach from the outset. Said approach involved a cloud-hosted database, user interfaces for document preparation and project information editing, and an API to transmit content. The key learning legacy is the focus on the data within the reports first, rather than the reports themselves. This novel solution organizes qualitative data and improves upon existing BIM practices to deliver increased efficiencies on the project from data management and access, to report generating.
Acknowledgements
Contributions by:
Matt Graham
James Barry
Shania Sandher
References
- Azhar S. Building Information Modeling (BIM): Trends, Benefits, Risks, and Challenges for the AEC Industry. Leadership and Management in Engineering [Internet]. 2011 [cited 2023 Sept 21].
Peer review
- Jon HudsonHS2 Ltd